ogmini - Exploration of DFIR
Having fun while learning about and pivoting into the world of DFIR.
About Blog Posts by Tags Research Talks/Presentations GitHub Search RSS
Magnet Virtual Summit 2025 CTF - AAR "All of my work is gone!"
by ogmini
 At least two solutions are possible.
At least two solutions are possible.
Continuing with my writeups on my “fails” or the ones I just couldn’t figure out in the timeframe alloted. I want to talk about how I went about trying to solve the challenge and where I went wrong. This should help me in the future by highlighting weaknesses and areas for improvement. Each post will focus on just one “fail” challenge. You can find all my writeups page.
All of my work is gone
Title: All of my work is gone! Description: How many shirts are in the ad?
This challenge was under the Chromebook section and worth 75 points. It was the hardest challenge in the category.
My Process
- The Marketing Advertisements.7z file is an obvious solution. It is password protected; but we know there is a TypeShirt_Ad.jpeg file in side.
- Do we know the password? Can we crack it?
- We know that Mary password protected this 7z file from the emails and her physical access to the Chromebook.
- I was pretty sure the password was in the sucess.txt.txt file. During the competition, I was unable to recover the contents of that file. Previous AAR can be found page. So close, yet so far.
- Is there some remnant of this jpeg anywhere on the Chromebook?
- Do a simple file search and get no hits.
- I did not scroll through all the images found by Magnet AXIOM on the device.
Actual Solution
Turns out there are two solutions to this!
Password Solution
It appears this was the intended solution that assumed you were able to recover the contents of the sucess.txt.txt file. Using the password “marywuzhere” unlocks the Marketing Advertisements.7z file and we can open the TypeShirt_Ad.jpeg. The image contains 8 shirts.
Image Carving Solution
Andro6 solved this problem by using Magnet AXIOM and searching for images that contained shirts. It turns out that Magnet AXIOM was able to carve the image out of the Google Chrome Cache. In their writeup, Andro6 didn’t give details on where Magnet AXIOM actually carved the image from but I had a suspicion it was in the Google Chrome Cache.
I wanted to verify this finding and we know that Ruth was playing with AI and it is possible they created the image using one of the AI image generators online. I pulled out the Google Chrome Cache located at home\user\2bf8ce8f9e4afef8b6f08991553f783299bf8747\Cache\Cache_Data and ran it through Nirsoft Chrome Cache View. Nothing obvious leaped out. Cheating a little bit, we know that the original TypeShirt_Ad.jpeg file is 724 KB. Looking at all the cache files there are a few that are slightly larger and the c8879684c431398e_0 file is a good candidate to take a peak at.
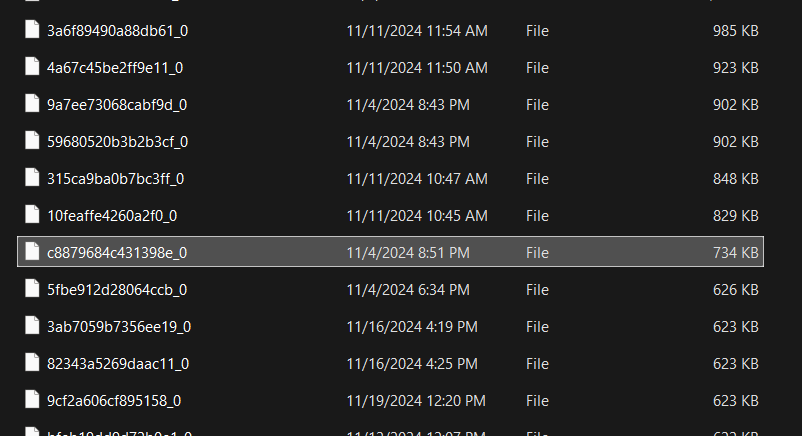
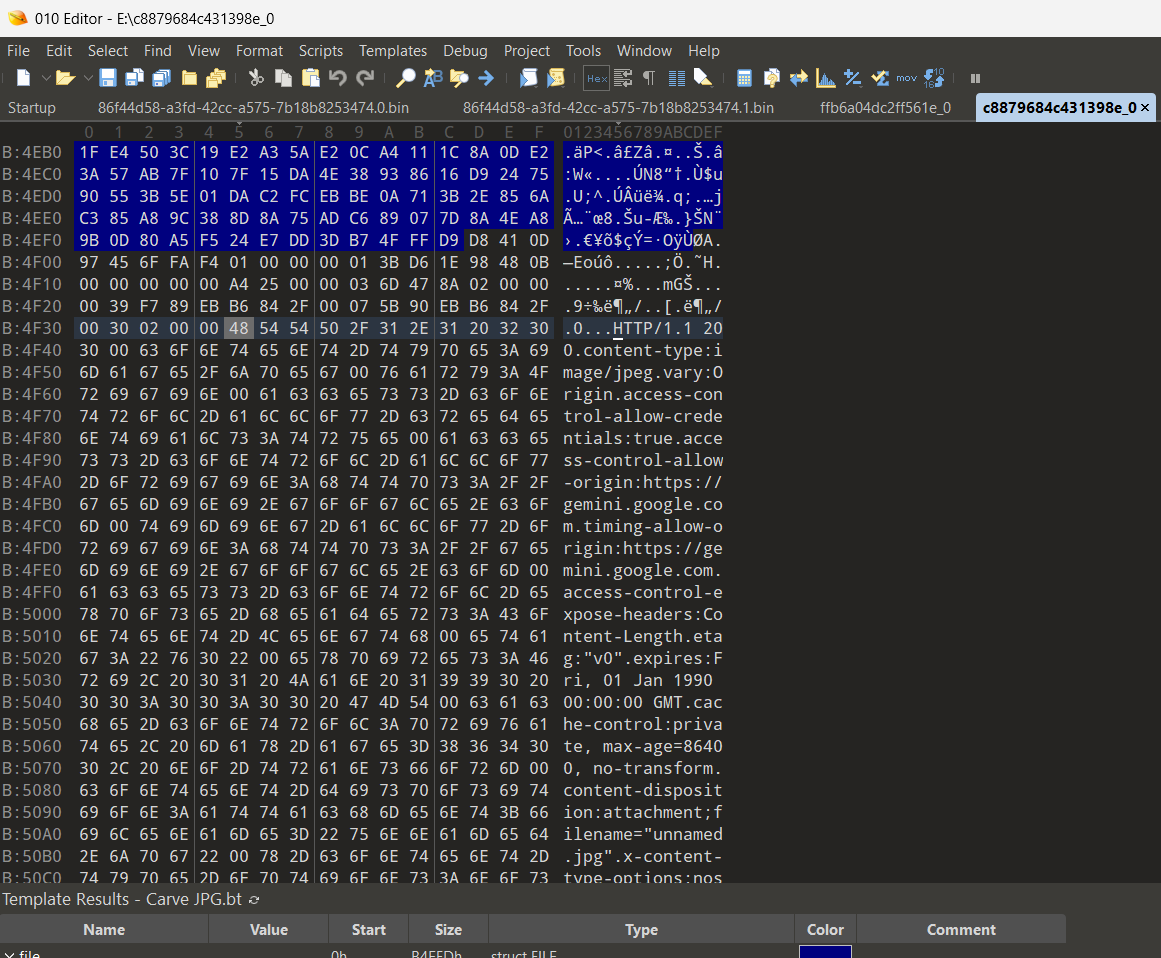
I open up the cache file in 010 Editor and scrolling down some text leaps out at me. Specifically “JFIF” and the magical 0xFFD8FFE0! Seems this binary file has image data embedded in it. I whip up a quick Binary Template to just highlight the relevant data and proceed to manually carve that data out into a new file.
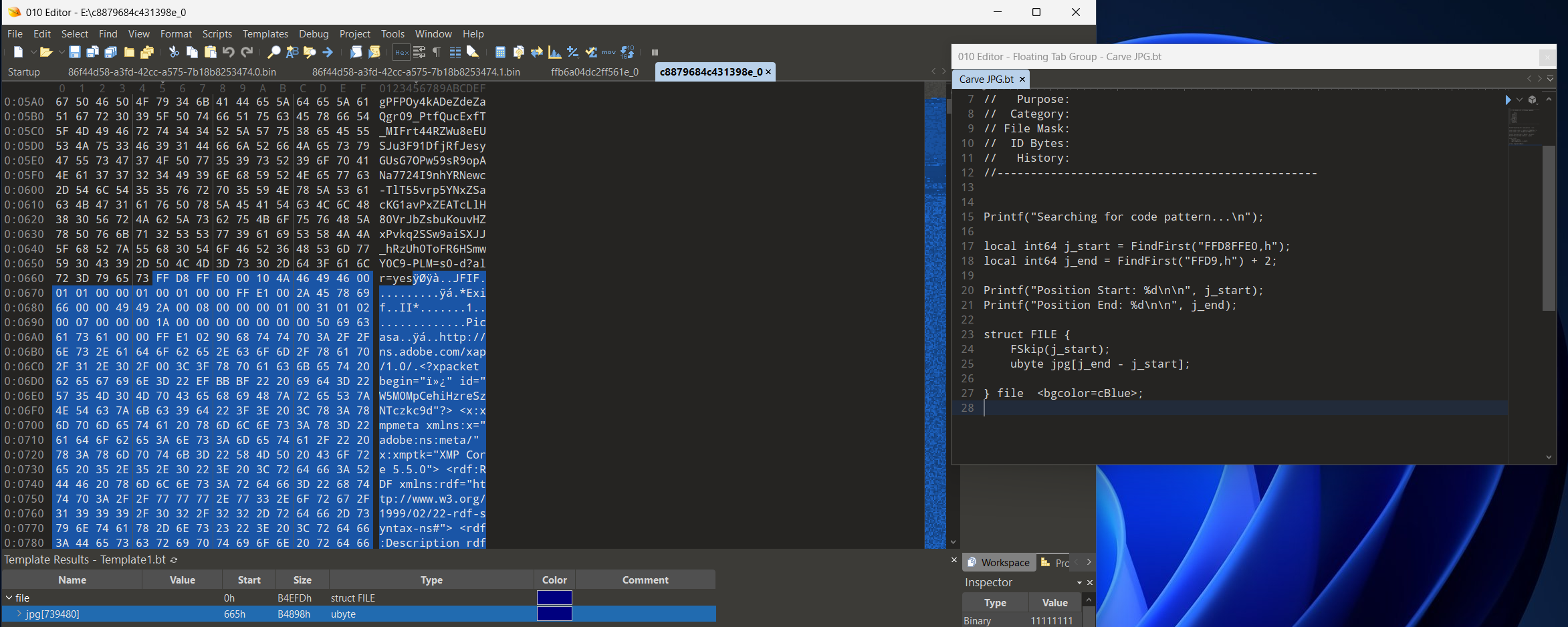
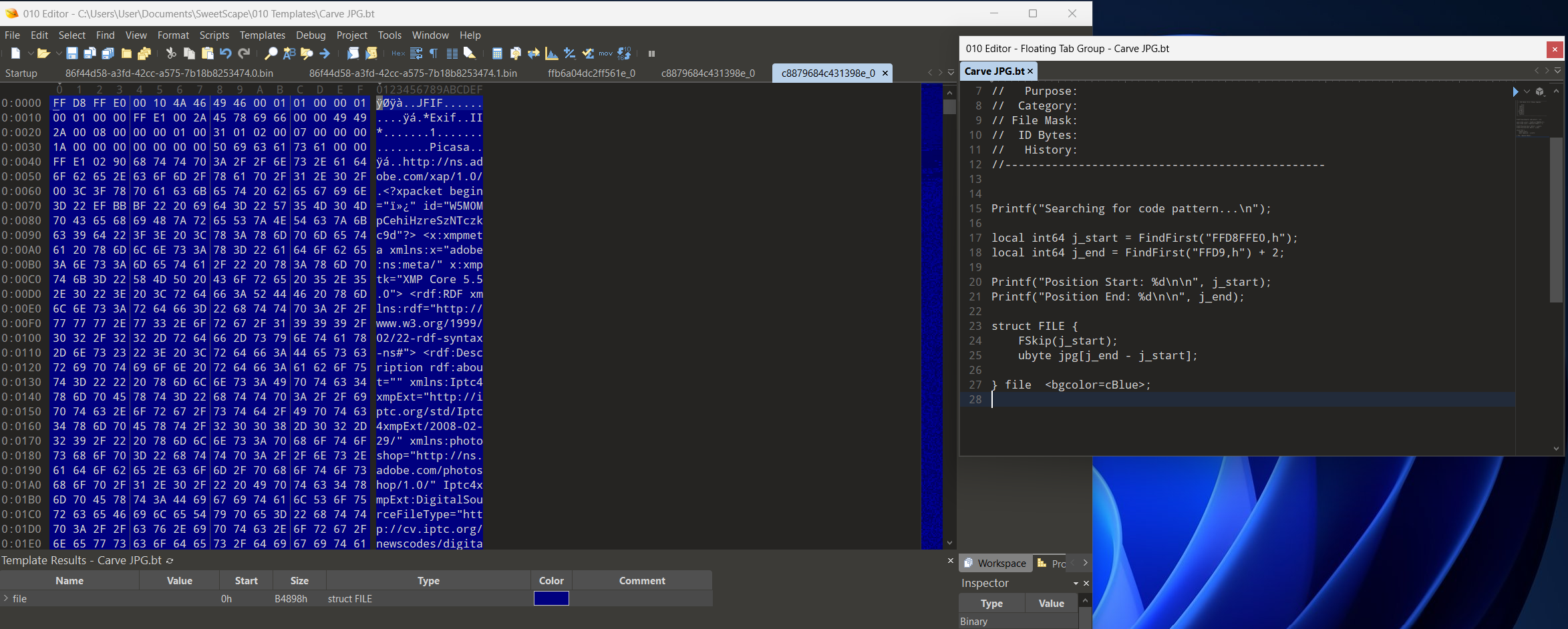
Looking more closely at the JPG in 010 Editor and using an existing Binary Template highlights some interesting facts about where this image possibly originated from. We see references to Picasa, Photoshop, and most importantly a credit to “Made with Google AI”.
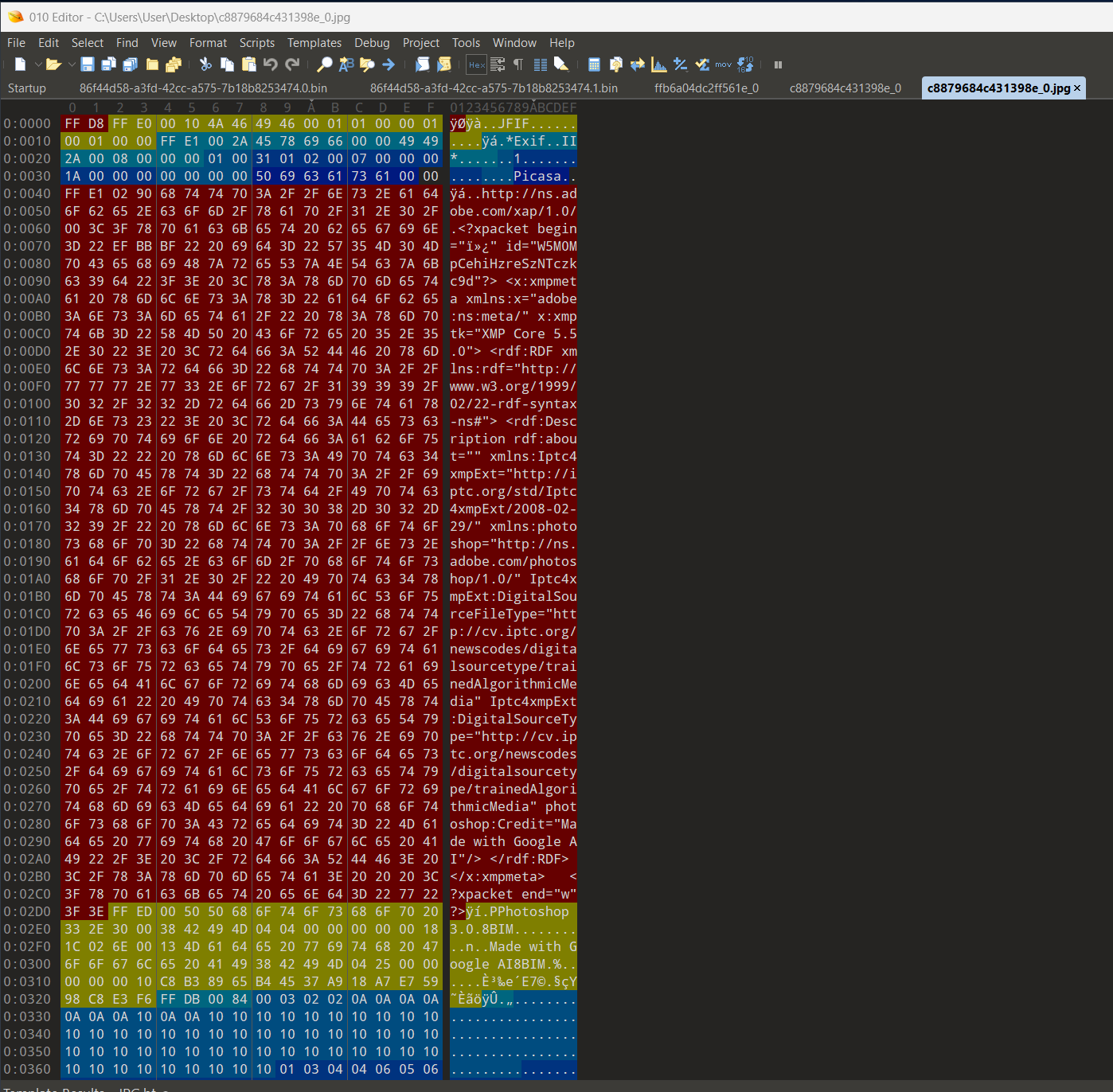
The uncarved cache file also has some interesting HTTP Headers present. We see references to gemini.google.com, content-type of image/jpeg, and status codes.
And the payoff of all that work is the carved JPG which matches the one recovered from the 7-Zip file. They both have an MD5 hash of 3ef281c6b5377679c8e63a433a602068

Lessons Learned
- There are often multiple ways to arrive at a solution. Realistic actions on a computer will result in multiple artifacts. This really shows the importance of a real world scenario for CTFs.
- Knowing how to manually carve is still important to verify and understand where tools find artifacts.
- Is there a tool other than Magnet AXIOM that could have carved the image out?
- It seems that ChromeCacheView has limitations.